 arXiv
arXiv Hugging Face
Hugging FaceMethods
We conducted a systematic review, as illustrated below. We began with 46,114 articles drawn from the proceedings of ICML, ICLR and NeurIPS (accessed via proceedings websites) between 2018 and 2024, and from ACL, NAACL and EMNLP between 2020 and 2024 (accessed via ACL Anthology).
We identified and selected articles whose titles or abstracts contained the keywords 'benchmark' and either 'LLM' or 'language model.' Then, we conducted a series of manual and automated filtering steps to select 445 articles included for final review.
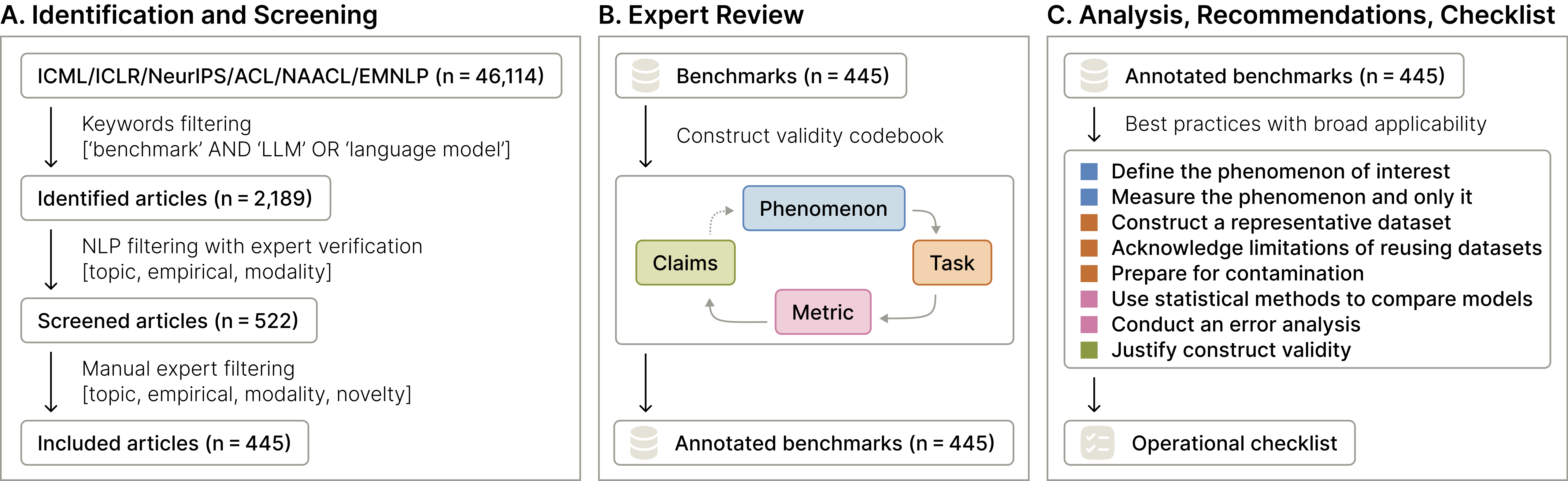
Systematic review process. (A) Identification and screening from relevant proceedings. (B) In-depth review and annotation of included benchmarks. A phenomenon is operationalised via a task, scored with a metric, to support a claim about this phenomenon. (C) Synthesis of best practices.
Results
We reviewed each benchmark article with a twenty-one item questionnaire. Twenty-nine experts in NLP and ML contributed to this effort.
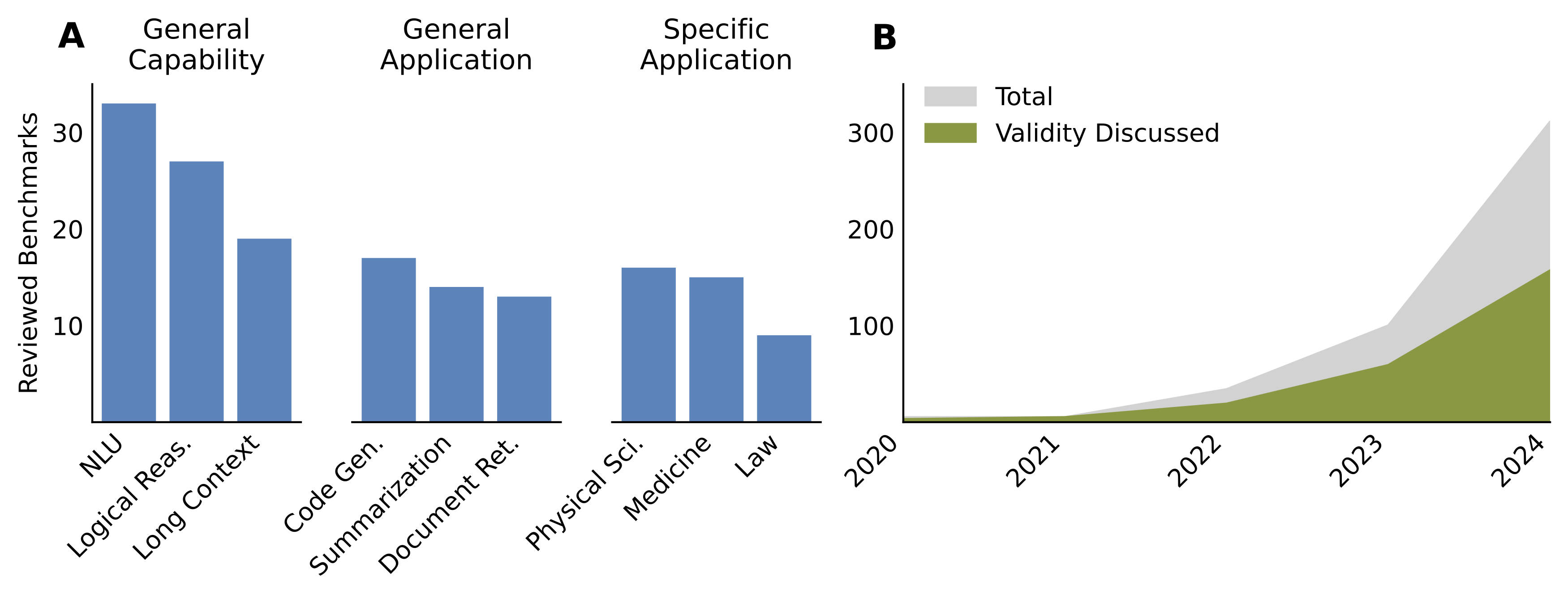
Summary of reviewed articles. (A) Three most common categories of benchmark phenomena, grouped into general capabilities, general applications, and specific applications. (B) Number of articles by publication year and number which discuss the construct validity of their benchmark.
Key codebook results. The distribution of codebook responses on selected items. In each column, the options are ordered from most to least preferred for high construct validity. The shaded area indicates the benchmarks that follow the best practices for all five items.
Construct validity checklist
Informed by our systematic review, we provide eight recommendations to ensure the construct validity of your benchmark:
- Define the phenomenon
- Measure only the phenomenon
- Construct a representative dataset for the task
- Acknowledge limitations of reusing datasets
- Prepare for contamination
- Use statistical methods to compare models
- Conduct an error analysis
- Justify construct validity
See our interactable checklist, including PDF and LaTeX versions, on this page.